

Multi-Agent Coding, Without the Chaos
Practical patterns for splitting work, coordinating execution, and reviewing results in real codebases

This publication is by members of the Algorythm Community. A network of 20k+ black software engineers sharing technical insights across all fields of software development. Join us on LinkedIn, Facebook and Subscribe for more insights.
This is Part 9 of a 10-part series on AI-assisted development workflows. Find the series here
I had six agents running in parallel across six git worktrees — separate working copies of the repo, each on its own branch, sharing the same git history but with their own files on disk. A large migration, broken into independent pieces — each agent with its own worklog, its own branch, its own PR. The editing portion went fine. Diffs were clean. Plans were being followed.
Then they all started running tests at the same time.

193 GB of memory. On a 64 GB machine. The system was swap-thrashing so hard I couldn’t even open Activity Monitor. I had to force-reboot.
Editing is cheap. Execution is the bottleneck. A swarm doesn’t become powerful when more agents start writing. It becomes powerful when coordination, verification, and review scale faster than code generation. Six agents writing code in parallel barely registers on the CPU. Six agents each spinning up Gradle daemons, compiling Kotlin, and running test suites? That’s six independent build systems fighting over the same physical resources.
And memory isn’t even the only wall. Kotlin’s build cache hardcodes absolute file paths. Every worktree I spin up does a full cache invalidation — 40+ minute initial builds on Reddit’s codebase. Another developer on an M2 Pro Mac reported thermal throttling running a single agent loop on a complex Android app. Two instances? Physically impossible.
For web developers with fast builds and no compilation cache, multi-agent localhost might work fine. For compiled languages with heavy build systems, it’s currently impractical. The fix is cloud agents, and that’s where this is all heading.
The Multi-Agent Spectrum
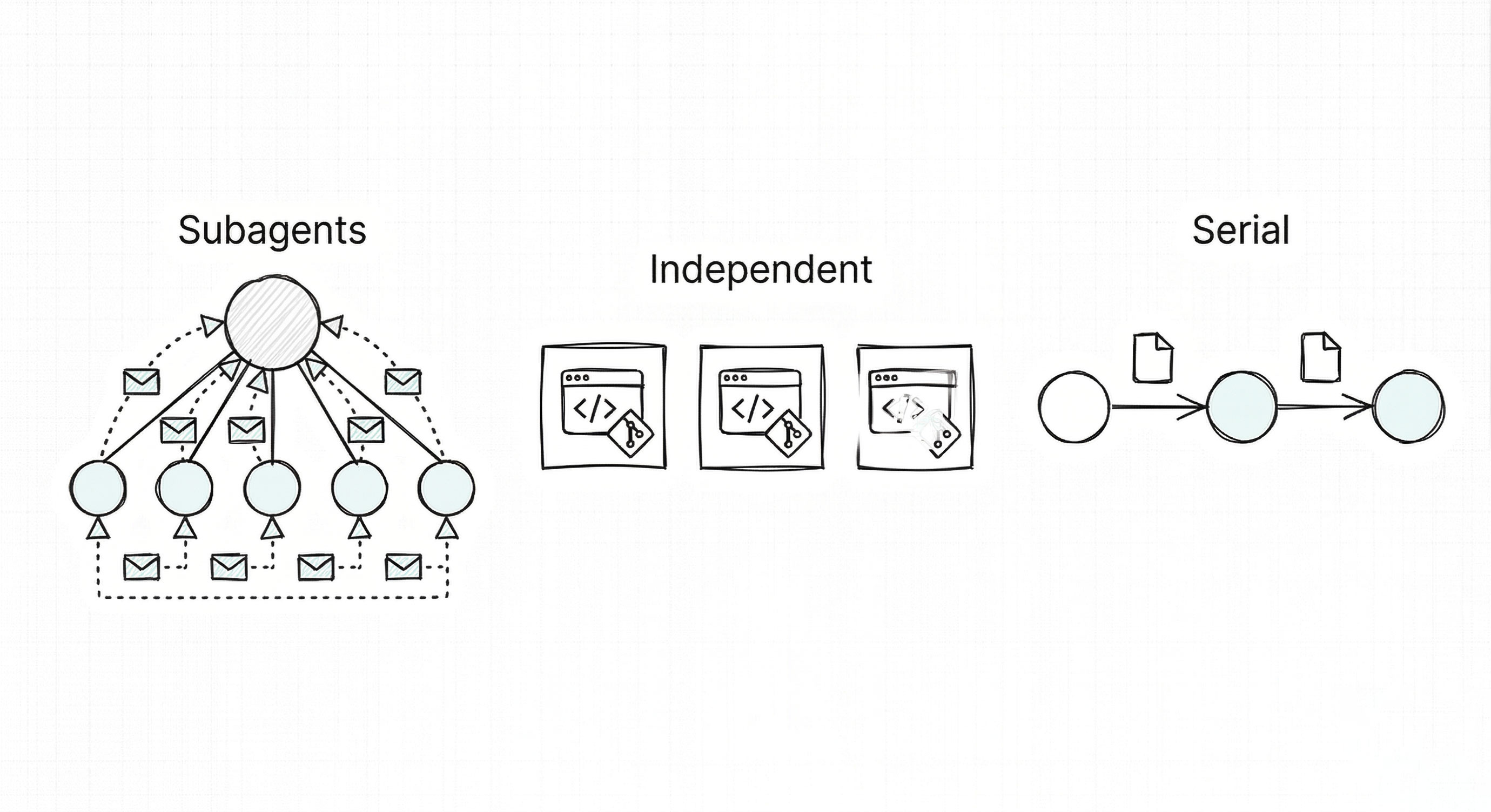
There are three ways to run multiple agents, and which one you reach for depends on what you’re doing and what your system can handle.
Subagents run inside a parent agent’s session, each with its own context window and prompt. The parent only receives the summary, not the full search trail — subagents actually save context by doing deep work in their own windows. Subagents save context, but they can’t coordinate laterally. They only talk to the parent.
I learned the limits of this the hard way. On Sparkpass, a Next.js ticketing app, the product spec had drifted from the codebase. I planned a 7-domain parallel audit — Auth, Events, Payments, Wallets, Dashboard, Attendee, Admin — each subagent with its own slice of the spec and code locations to examine. The plan was clean. The machine couldn’t handle it.
Too many subagents running simultaneously hit local resource limits, and the whole thing ground to a halt. I had to fall back to running the domains serially, one agent at a time. That’s where the NEXT_AGENT_PROMPT pattern came from — each agent wrote a structured handoff of what it found, what was left, and what the next agent should be aware of. The serial version found 23 gaps across the codebase. The parallel plan was better in theory. The serial fallback actually shipped.
Independent sessions are separate editor or terminal windows, each in its own git worktree, with its own agent. No shared context at all. The key is to design the work so agents don’t need to coordinate — choose tasks that are genuinely independent. Separate features, documentation, isolated modules. If two agents touch the same file, you’ve picked the wrong tasks to parallelize. On platforms with fast builds, independent sessions will usually beat serial execution on wall-clock time.
Serial handoffs are what the Sparkpass audit fell back to — and they worked. No compaction loss because nothing carries over in-context; the handoff file is the context. Steve Yegge’s Beads system takes this further with an issue tracker as shared working memory, bd readysurfacing unblocked tasks, and a dependency graph enforcing ordering. Serial makes sense when a task is genuinely unparallelizable or when you’re up against device constraints like the Gradle and memory walls from earlier.
The decision rule is simple: subagents for parallel research, independent sessions for isolated implementation, serial handoffs for dependency-heavy or long-lived work. Most real workflows mix all three.
When do you actually need parallel agents? Sergio Sastre Florez, an Android GDE, pushed back on this: if agents are running long enough to parallelize, the output is probably too large to review carefully. Large parallel outputs hide duplication and unnecessary code.
He’s right. Most tasks don’t need parallelism. A task too simple for parallel execution wastes more time on setup than it saves.
And there’s a hidden cost beyond compute: every agent you spawn makes you a manager. You’re context-switching between worktrees, checking progress, unsticking blocked agents, reviewing diffs across multiple PRs. Engineers are used to a maker schedule, not a manager schedule. Three parallel agents can drain you faster than one focused session if you’re not careful.
When parallel actually helps: large migrations with battle-tested skills, epics with independent tickets, features with parts that don’t depend on each other. And you shouldn’t decide this yourself. Ask the agent: “Can this work be parallelized?” Then verify the proposed split against file overlap, dependency chains, and review burden. It might say no. That’s a valid answer.
Specialists Beat Generalists
Marvin Minsky’s Society of Mind argues that intelligence emerges from many simple agents operating at different abstraction levels. High-level agents coordinate strategy. Mid-level agents execute specialized tasks. Low-level agents handle mechanical operations.
I learned the difference between horizontal and vertical partitioning building Eagle Eye, a screenshot review system. The first version used 3 generalist subagents — each one reviewed a batch of screenshots for everything: contrast, clipping, layout, touch targets. Fifteen things to check per screenshot. Low contrast text on the settings screen shipped because all three generalists checked for contrast and none of them owned it. When everybody’s responsible, nobody’s accountable.
The fix was vertical partitioning. Instead of 3 generalists reviewing batches, I proposed 4 specialists reviewing all screenshots for one concern each:
Text Contrast Agent — WCAG violations across all screenshots
UI Clipping Agent — content overflow across all screenshots
Layout Agent — design system spacing violations
Touch Target Agent — interactive elements below 48dp
A coordinator aggregates their findings into a unified report. Each specialist has one mandate. Narrower prompts mean lower token costs. And because each agent owns exactly one concern, things are less likely to fall through.
The same pattern showed up in Reddit’s Flag Lifecycle Agent — an autonomous system that discovers stale feature flags in the codebase, validates them against production experiment data, and generates cleanup PRs. Three abstraction layers:
Orchestration — discovery, validation, complexity scoring, spec generation
Specialists — Planner, Coder, Reviewer (a 3-agent loop inside a cloud sandbox)
Platform — sandboxed execution, git operations, PR creation, experiment data APIs
Each layer communicates via structured data. The orchestrator doesn’t write Kotlin. The coder doesn’t know how to query experiment data. The platform doesn’t know what a flag cleanup is. Clear boundaries, clear responsibilities. In Phase 1 testing, this architecture cleaned up 7 flags in a single day at $8.79 total — all 7 PRs passed CI.
The pattern generalizes across stacks. I used the same layered architecture in AutonomyOS, a Next.js/TypeScript agent platform. Events trigger proposals, proposals decompose into missions, missions break into concurrent steps — each step executed independently, results aggregated by a coordinator. Different language, different domain, same shape: coordinator at the top, specialists in the middle, platform at the bottom.
The Conductor Pattern
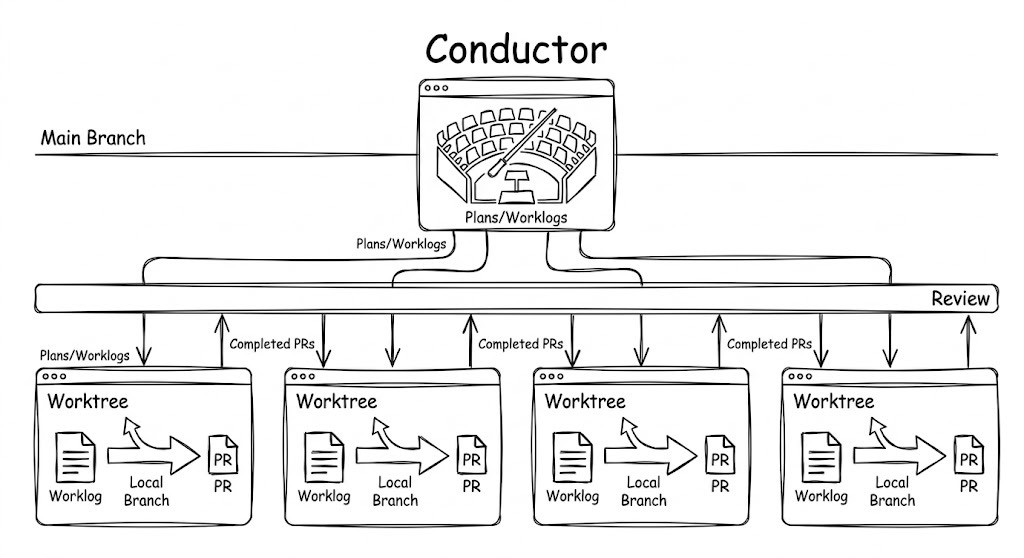
Think of orchestrating parallel agents like a CPU scheduler. Independent tasks get parallelized. Dependent tasks stay serial. You set the goals and constraints. The AI proposes the schedule.
In practice, this means one main editor window stays on develop and orchestrates. It creates git worktrees, writes worklogs, and delegates. Each execution window opens in its own worktree, follows its assigned worklog, commits, pushes, and opens a PR. The main window never implements. It plans and coordinates.
The migration from the opening used this pattern. Each worktree got a dedicated worklog (TDD plan, verification plan, invariants, a checklist of surprises and notes) and a separate PR — independent, not stacked.
The orchestrator agent is the key upgrade. Instead of manually deciding what to parallelize, the orchestrator looks at all in-progress worktrees and picks up the next task with minimal conflicts. Ask the agent: “Look at the work remaining and the worktrees already running. What should the next agent pick up?” It considers file overlap, module boundaries, and dependency chains. It might tell you everything remaining is serial. That’s fine.
Verification makes this trustworthy. Without closing the loop (TDD, red-green commits, a verification plan), the AI will push slop. Every agent following a worklog has a contract: write the test, watch it fail, write the implementation, watch it pass, commit at each transition. The worklog structure is what separates parallel execution from parallel chaos.
And the worklog survives compaction. When a long-running agent hits context limits and the conversation gets compressed, the worklog on disk is still intact. The agent can re-read it and restore full context. This is what makes parallel agents viable for complex PRs, not just trivial ones.
This is still pre-background-agent territory. You’re manually triggering each agent. You’re reviewing each PR. But you’ve separated orchestration from execution. Skills and worklogs are now executable artifacts.
More agents writing code means more code to review. That review layer is its own multi-agent problem.
Who Reviews the Agents?
As execution parallelizes, review must also become layered and partially automated, or the human becomes the bottleneck again. In Part 2, a second model caught an issue the first one missed entirely. Different models have different blind spots, which is exactly why you want AI handling the mechanical review layer — missing imports, type inconsistencies, test coverage gaps — before a human ever sees the PR.
The principle: review must decompose into fast mechanical checks and slow human judgment. AI handles the first layer. Humans handle the second. Neither works alone at scale.
The specific tools matter less than the pattern. For my personal projects, I use Greptile for confidence scoring (a 2/5 score has consistently flagged real problems) and CodeRabbit for deep static analysis and auto-generated sequence diagrams. But any tool that gates the mechanical layer works.

Greptile’s confidence score flagging a critical issue — 2/5, with a clear explanation of why
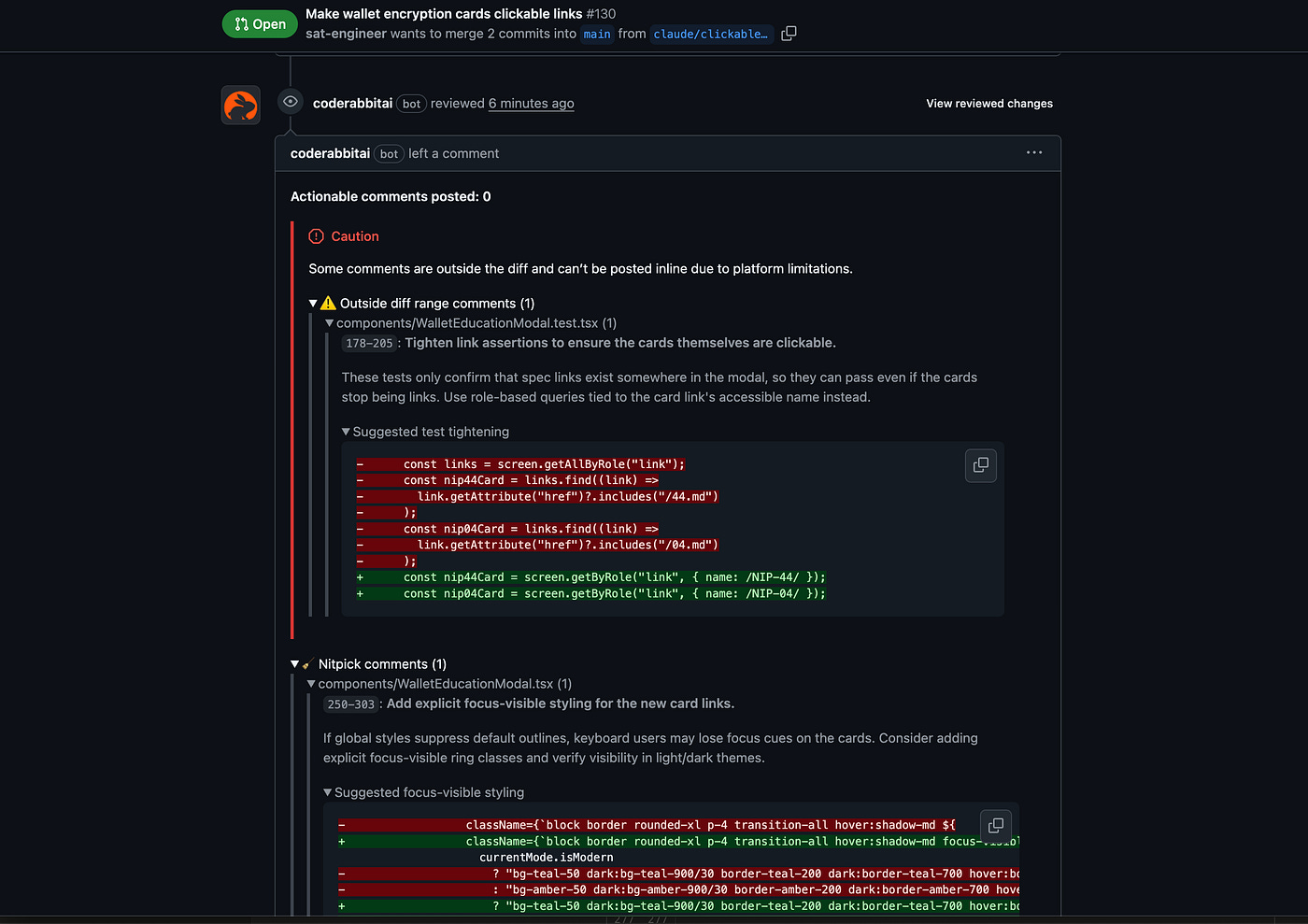
CodeRabbit catching test gaps and accessibility issues with suggested fixes
The workflow:
Agent writes code and tests
Push to branch, open PR
AI reviewer scores confidence and flags mechanical issues
CI passes (tests, lint, build)
Human reviews with mechanical analysis already done — primarily architecture and product decisions
But you’re still in the loop. Still triggering every agent. Still reviewing every PR. And flag cleanup is just one use case. Unused dependency removal, lint upgrades, library migrations, dead code cleanup — every piece of tedious maintenance work that devs do on a regular basis is a candidate for the same pattern: discover, verify, ship.
A self-driving codebase doesn’t begin with autonomy. It begins when work becomes structured enough to delegate safely.
Follow Andrew to catch the release of Part 10 for where this is heading: cloud agents, autonomous maintenance loops, executable worklogs, and the full Redit Flag Lifecycle case study that shows how multi-agent systems can safely discover, verify, and ship real code changes.
About The Author

Andrew Orobator is a Senior Android Engineer @ Reddit, Musician and Public Speaker.
 | A guest post by
|
Six agents in parallel is exactly where things get interesting and also where they fall apart fastest. The review step you describe is doing the same job as the YOLO classifier in Anthropic's leaked source.
I went through their actual coordinator implementation at https://thoughts.jock.pl/p/claude-code-source-leak-what-to-learn-ai-agents-2026 The way they handle result aggregation versus delegation is more explicit than I expected. Main thing that changed how I think about it: the coordinator isn't just routing, it's carrying forward state that individual agents can't see.