

How to Build a “Find Nearby” Feature That Actually Scales
How R-trees make nearby-location queries fast in PostgreSQL and other database systems

This publication is by members of the Algorythm Community. A network of 20k+ black software engineers sharing technical insights across all fields of software development. Join us on LinkedIn, Facebook and Subscribe for more insights.
I recently worked on a project that required querying data by geographical coordinates, which was my first experience with a production-grade app that needed this feature. I started by trying to use a WHERE clause to query data within specific geographic coordinates (latitude, longitude). This worked but was painfully slow and impractical for a production environment.
So I did some research on ways to make this work efficiently with minimal latency in response. I found a working solution using the PostgreSQL extension PostGIS, and I then decided to dig deeper into the topic to better understand what was actually happening under the hood.
Why Traditional Indexes Fail
While B-trees can index multiple columns at a time (composite indexes), they fundamentally sort data linearly. Because of this, when you need to query data using true multi-dimensional criteria—such as searching within a bounding box using latitude and longitude—B-trees become inadequate and inefficient.
Imagine you have a table with 1 million store locations, each defined by latitude and longitude. You want to quickly find all stores within a 5 km radius of a customer’s location. With standard B-tree indexes, you’d create:
CREATE INDEX idx_latitude ON stores(latitude);
CREATE INDEX idx_longitude ON stores(longitude);Your initial bounding-box query might look like:
SELECT *
FROM stores
WHERE latitude BETWEEN 40.7 AND 40.8
AND longitude BETWEEN -74.1 AND -73.9;However, this approach:
Requires two separate scans (latitude and longitude).
Forces an expensive intersection operation in your application code.
Requires further filtering to verify distances precisely.
Quickly degrades performance as the dataset grows because B-trees can’t inherently manage multi-dimensional searches efficiently.
Why Geospatial Indexes Exist
Imagine typing “Bus stops near me” into Google and instantly getting the five closest stops around you with no lag or missed results. That’s geospatial indexing at work. Geospatial indexing is a method for efficiently querying location-based data by latitude and longitude (2D) and sometimes by altitude (3D). Many popular applications today use geospatial indexing to deliver quick, efficient results to their users, leveraging latitude and longitude pairs.
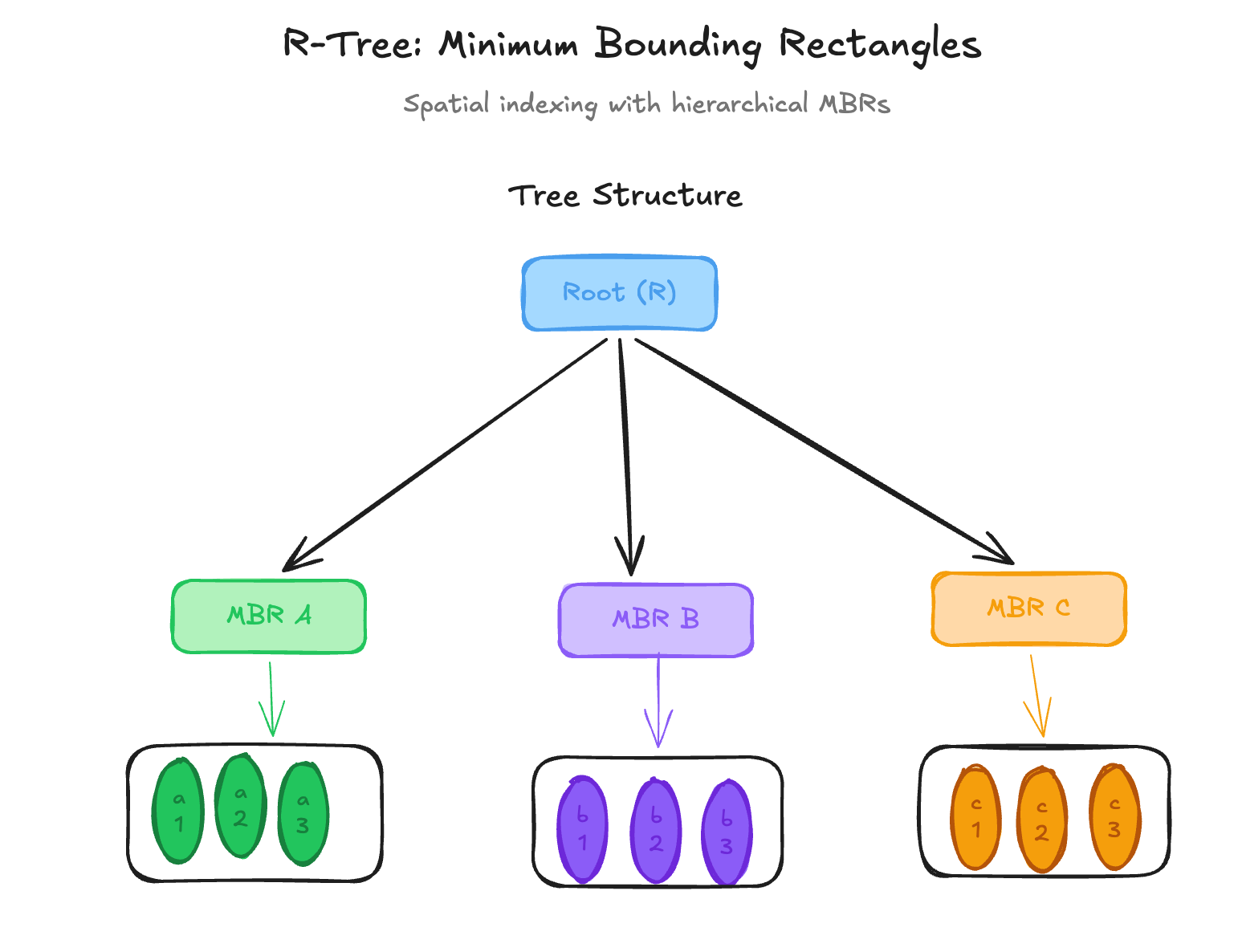
Unlike traditional indexes such as B-trees, geospatial indexes are designed to handle multidimensional spatial data. A spatial index typically organizes data in a hierarchical structure composed of:
Leaf Nodes: The leaf nodes contain bounding rectangles and references to the stored geometries.
Interior Nodes: The interior nodes store larger bounding regions that encompass their child nodes.
During a query, the database traverses only the branches whose bounding regions intersect the search area. This allows the system to quickly eliminate large portions of irrelevant data. The most widely used structure for achieving this is the R-Tree.
R-Trees
An R-Tree is a tree-based data structure used to efficiently store and retrieve spatial (location-based) data. It follows the same idea as a B-Tree, but instead of indexing scalar values, it indexes spatial objects such as points, lines, and polygons.
The key idea behind an R-Tree is the use of Minimum Bounding Rectangles (MBRs).
An MBR is the smallest rectangle that fully contains a spatial object. These rectangles allow the index to group nearby spatial objects together, making spatial queries much faster. Most spatial databases, such as PostGIS, implement R-Tree behavior through GiST indexes, which generalize the R-Tree structure for multiple data types. In PostgreSQL, creating one is as simple as:
CREATE INDEX ... USING GIST (location)and PostGIS handles the rest.
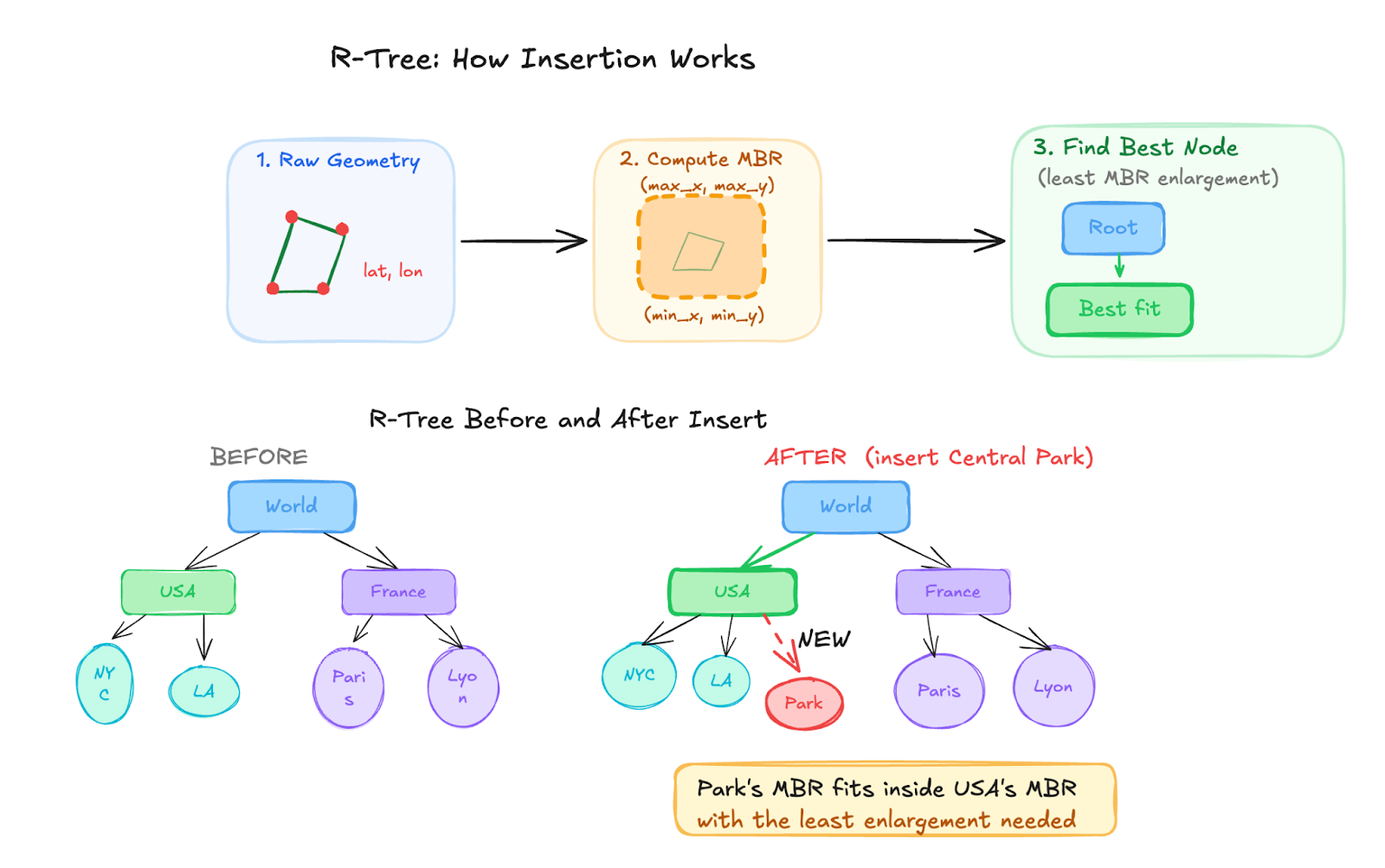
Inserting Data
When geographical data is inserted into a database, the spatial object is stored in the table, and the spatial index then computes the object’s Minimum Bounding Rectangle based on its coordinates (latitude, longitude) or (latitude, longitude, and altitude). This rectangle is inserted into the R-Tree structure.
Each node in the tree stores bounding rectangles that cover all spatial objects contained within that node. As more data is inserted, nearby objects tend to be grouped under the same nodes. If a node exceeds its capacity, it is split into multiple nodes, and the tree structure adjusts accordingly. The node capacity for an R-Tree, like a B-Tree, depends on the page size (generally 8 kilobytes).
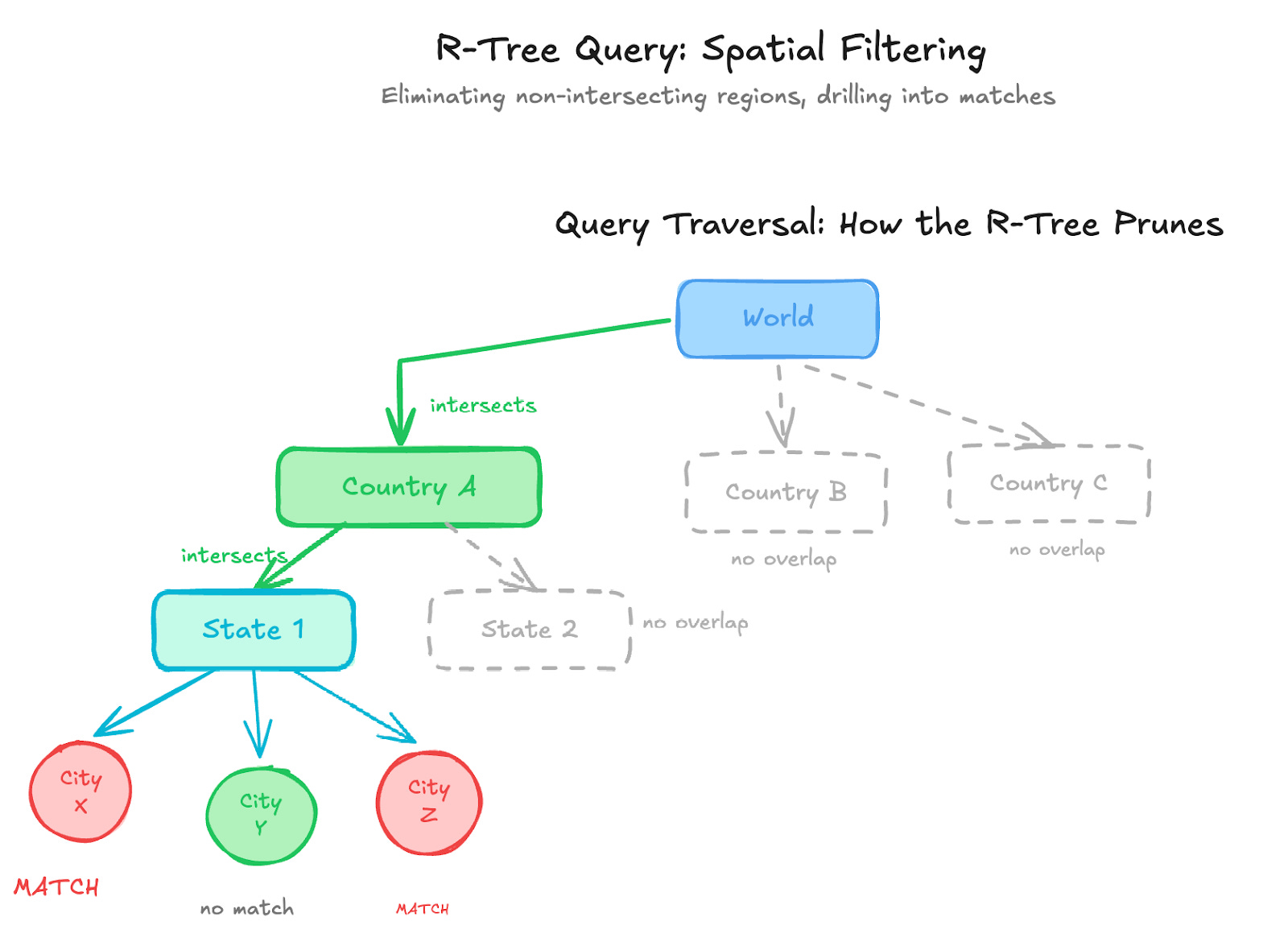
Querying Data
During queries, the R-Tree quickly eliminates regions that cannot contain relevant results by checking whether their bounding rectangles intersect the search area. Only candidate geometries that pass this initial filter are then evaluated with precise spatial operations.
A simple latitude/longitude WHERE clause feels like it should be enough until your dataset grows, and queries that took milliseconds start taking seconds. The problem isn’t the query, it’s the index behind it.
Geospatial indexing solves this by organizing spatial data into structures like R-trees, which group nearby objects using Minimum Bounding Rectangles and traverse only the relevant parts of the dataset, skipping entire geographic regions that can’t match and running precise calculations only on a small set of candidates.
Tools like PostGIS bring these capabilities directly to PostgreSQL, enabling developers to build fast, location-aware systems, from mapping services and logistics platforms to ride-sharing and food delivery apps.
About The Author

Wilfred Chetat is a Senior Backend Engineer at UXE Security Solutions in Dubai, where he builds and scales high-throughput distributed systems for real-time video analytics. With over 6 years of Python development experience, he works across the full backend stack, from API design and message queues to databases and container orchestration.
Thanks for the deep dive Wilfred.
I have used and leveraged the benefits of tools such as PostGIS across SQL and NoSQL databases. But having this other layer of understanding does help a lot.
In our fast paced tech world to go higher it is essentially to go deeper, as you have done here. It is not good enough to know what to use, it is key that we know why it works.
This is a great read Wilfred! Thank you so much - this is relevant for the places I'm interviewing at so kudos to you 👏🏾